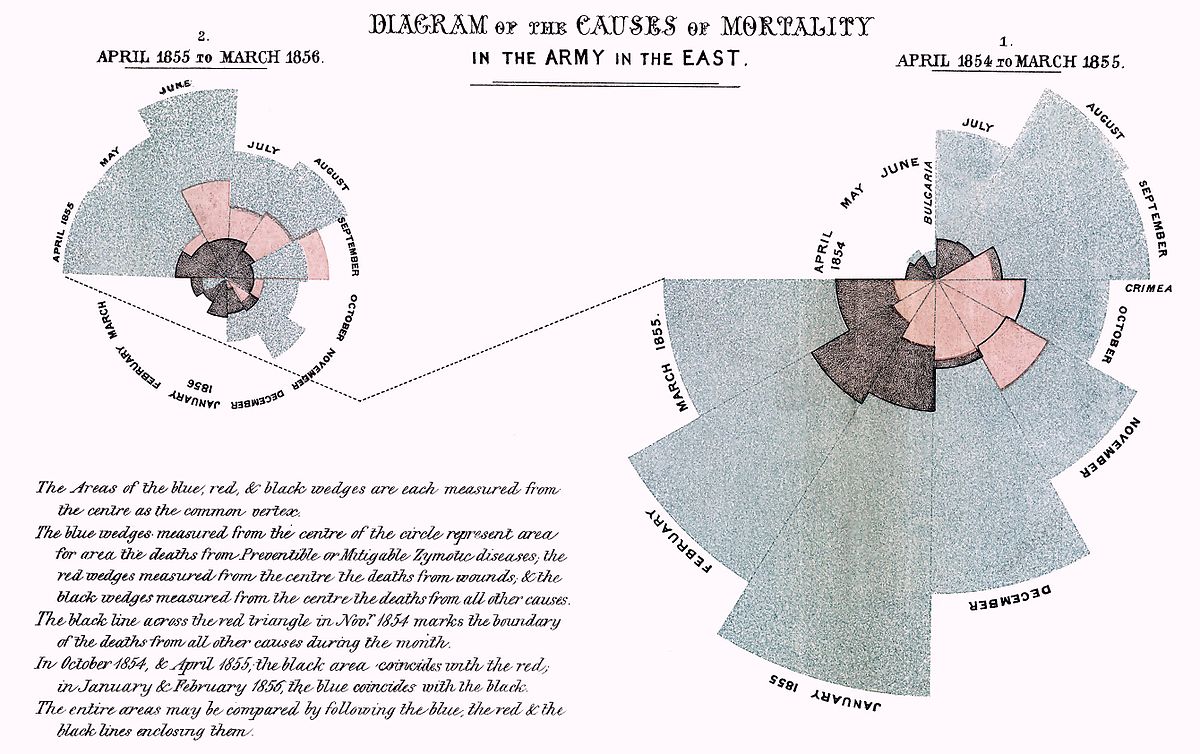
Don’t focus on tools, focus on storys“: Paul Bradshaw, britischer Online-Journalist und Blogger, hat mit dieser freundlichen Mahnung mich gemeint. Ganz bestimmt. Denn ich neige dazu, in meiner Begeisterung für neue Werkzeuge schnell mal die eigentliche Geschichte aus den Augen zu verlieren. Die aber steht auch im Datenjournalismus im Vordergrund und am Anfang eines Projekts.…
Datenjournalismus (1): Grundlagen