
Daten finden ist das Thema des zweiten Moduls im Online-Kurs „Doing Journalism with Data“, über den ich hier in einer kleinen Serie berichte. Experte ist Paul Bradshaw (Twitter), der an der Birmingham City University Online-Journalismus lehrt und das Online Journalism Blog betreibt. Er zeigt mir, wie man Daten automatisiert auslesen kann, nennt mir eine Alternative für den Fall, dass eine Website keinen RSS-Feed oder eigenen Mail-Alert anbietet, und erinnert mich an Möglichkeiten, die ich im Arbeitsalltag oft vergesse.
Finde, was du suchen musst
Die meisten Recherchen beginnen mit der Google-Suche. Und da hilft es ungemein, wenn man weiß, wonach man suchen muss. So lautet denn auch ein simpler, aber sehr guter Praxistipp von Paul Bradshaw: Recherchiere, welche Fachbegriffe dein Thema prägen. Offizielle Statistiken nutzen meist bestimmte Begrifflichkeiten, die nicht selten von unserem allgemeinen Sprachgebrauch abweichen. Wenn man sie kennt, findet man diese Daten schneller. Also: Zum Telefon greifen und Experten nach den gängigen Fachbegriffen zum Thema fragen.
Natürlich ruft Paul Bradshaw auch die oft vernachlässigten Möglichkeiten der erweiterten Google-Suche mit Hilfe von Operatoren in Erinnerung:
- „site:domain.com“, um nur auf einer spezifischen Website zu suchen
- „site:de“, um nur Treffer einer bestimmten Topleveldomain zu bekommen
- „filetype:xls“, „filetype:pdf“, „filetype:doc“, um gezielt nach Dateiformaten zu suchen
- Einsatz des Minuszeichens „-„, um bestimmte Websites, (Toplevel-)Domains, Begriffe oder Dateiformate auszuschließen
Hier die Google-Suchoperatoren auf einen Blick.
Die offiziellen Daten-Häfen anlaufen
Deutschland hinkt bei Open Data zwar schwer hinterher – das tritt in dem Kurs, der vor allem auf Datenportale im angelsächsischen Raum verweist, erneut schmerzlich zutage. Aber auch bei uns bewegt sich was. Immer mehr öffentliche Einrichtungen stellen Daten ins Netz. Die rechtliche Grundlage bei uns ist das Informationsfreiheitsgesetz von 2006. Es gewährt allen Bürgern Einsicht in amtliche Daten, sofern sie nicht personenbezogen oder sicherheitsrelevant sind. Immerhin: Ein Anfang.
Bradshaw empfiehlt aber durchaus auch einen Blick auf „weichere“ Datenquellen wie nicht-staatliche Organisationen, Fanclubs oder private Websites, die Statistiken zu einem bestimmten Thema verfügbar machen. Zur Einschätzung der Datenqualität sollte man sich natürlich auch hier unbedingt ein paar W-Fragen stellen: Wer sammelt die Daten wann und wie? Und: Gibt es andere Quellen, die einen Datenvergleich erlauben?
Paul Bradshaw verdanke ich den Hinweis auf ChangeDetection.com, wo man persönliche Mail-Alerts einrichten kann. Sehr praktisch, wenn man Änderungen auf Websites verfolgen will, die keinen RSS-Feed anbieten.
Scraping für Anfänger
Immer dann, wenn Datensätze eine feste Struktur mit wiederkehrenden Bestandteilen haben, sollte man über Scraping nachdenken. Ein kleines Programm oder Script kann das Herauskratzen oder -schaben von Daten übernehmen, wenn sie so beschaffen sind, dass auch eine doofe Maschine sie lesen und verstehen kann.
Mit anderen Worten:
If you need to do something more than once, get a computer to do it for you.
Charles Arthur, Guardian-Autor
Scraper kann man programmieren. Paul Bradshaw hat für Einsteiger das Scrapen mit einfachen Mitteln erläutert.
Scraping mit Google Spreadsheets
Mit Google Drive beispielsweise ist es möglich, Tabellen aus einer Website in ein Spreadsheet einzulesen. Eine einfache Anweisung genügt:
Importiere mir bitte ein HTML-Element. Es steht hier auf dieser Website, es handelt sich um eine Tabelle, und zwar die erste, die du auf der Seite findest.
Ok, weil man mit Google Drive anders reden muss: Die Formel, die man in die erste Zeile der ersten Spalte eines Spreadsheets schreiben muss, lautet
=ImportHtml(„URL“; „Abfrage“; index)
Unter „URL“ ist der Pfad zu der zu untersuchenden Website einzutragen. Die Art des auszulesenden HTML-Elements wird unter „Abfrage“ bestimmt – bei einer Tabelle ist hier „table“ einzufügen, bei einer Liste „list“. Und „index“ meint die Platzierung des unter „Abfrage“ definierten Elements auf der Seite. Soll die erste Tabelle auf der Website eingelesen werden, gehört hier eine 1 hin.
Ein Beispiel:
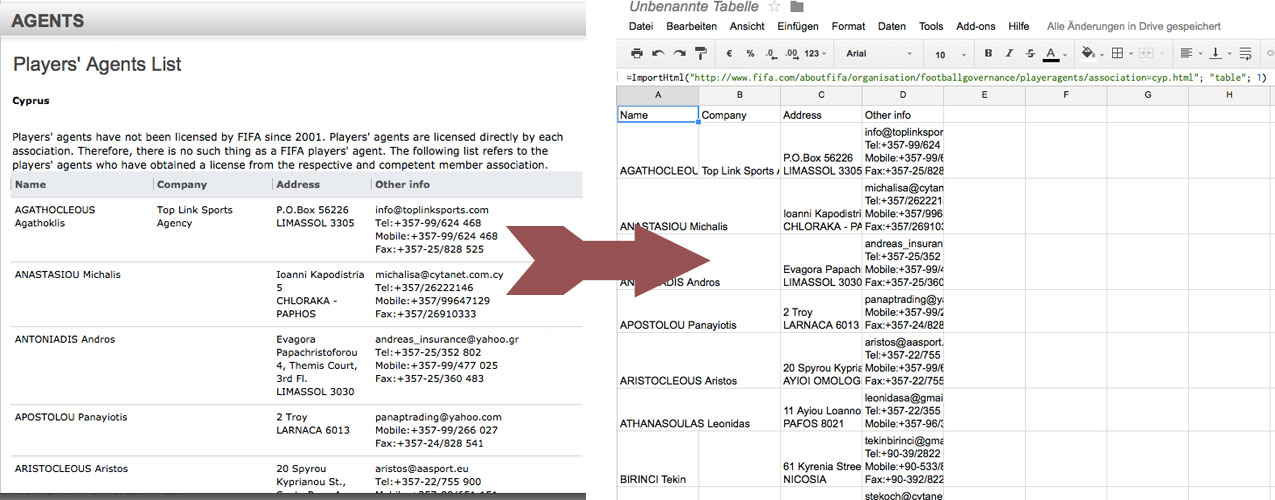
Mit einer einfachen Formel lassen sich Daten aus einer HTML-Tabelle in ein Google-Spreadsheet einlesen.
Scraping mit Outwit Hub
Ein mächtiges Scraping-Tool, das Daten aus mehreren Seiten ausliest, ist Outwit Hub. Das Prinzip ist schnell erklärt: OutWit Hub durchsucht beliebige Websites, listet ihre Bestandteile wie beispielsweise Tabellen auf und erlaubt, sie in verschiedenen Formaten wie CSV, XLS und anderen herunterzuladen. In einer eingeschränkten Version ist die Software kostenlos.
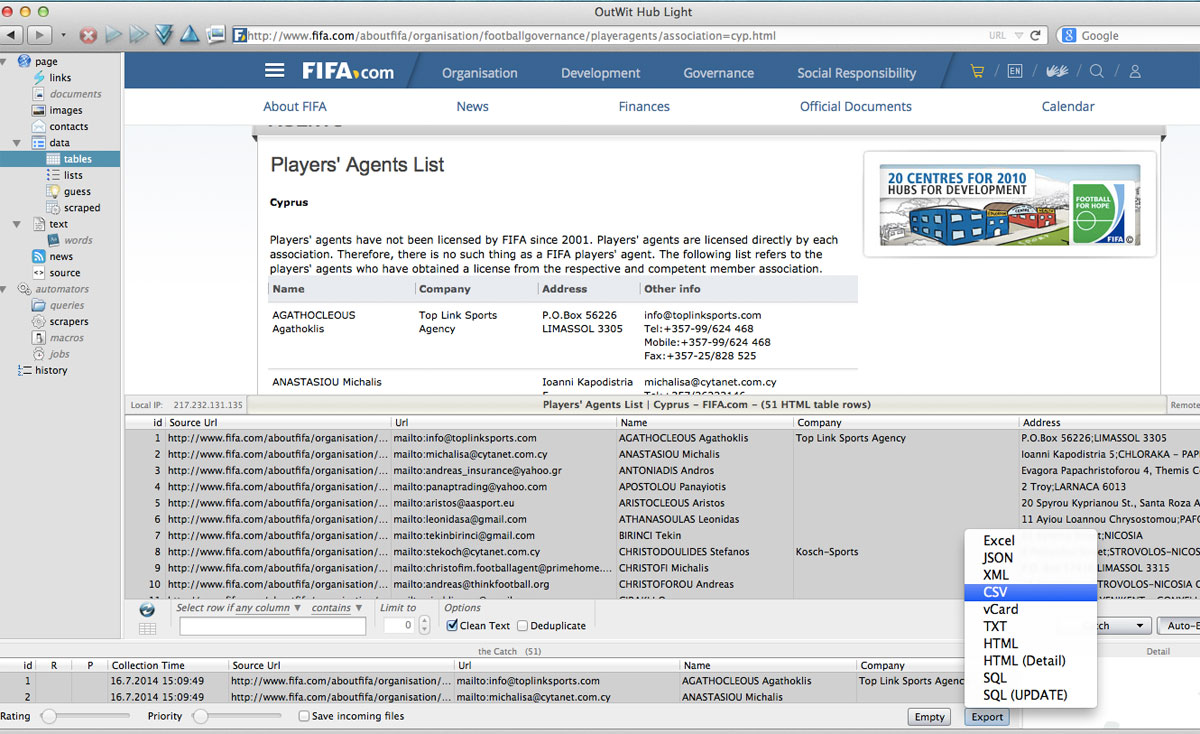
Scraping mit OutWit Hub
Mein Fazit aus diesem Modul:
Warum aufwändig, wenn es doch viel einfacher geht?